Q: When I OCR a document, I get errors such as “Could not initialize tesseract” , ” OCR library is not loaded: null” , “unable to initiate OCRBridge”. What are these errors and how can I fix them?
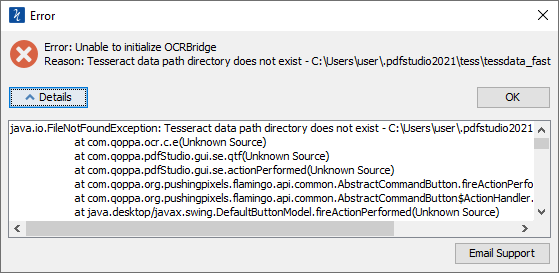
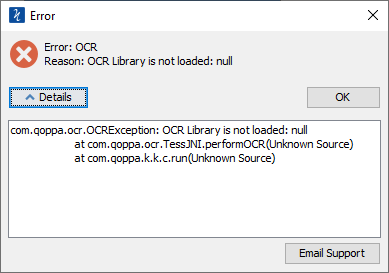
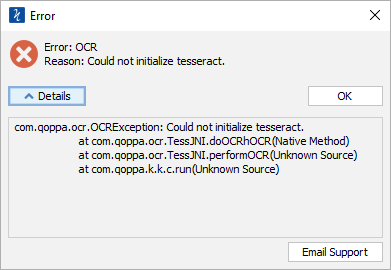
A: There are 4 possible reasons why you’ re seeing one of the errors above:
- If you are are running the latest version PDF Studio 2021 on Windows, there may be a package missing that you can install to resolve this error.
- You installed PDF Studio using the Unix installer. The OCR function is not available in the Unix installer. If you are running an older version of PDF Studio, you might see an error. In most recent versions, users will be prompted when trying to start OCR. To solve this issue, if you are running on Linux, reinstall PDF Studio using the Linux installer instead.
- You have Unicode / CJK characters in your username home folder, which leads to PDF Studio not being able to access the languages files in your user home folder.To solve this issue, you will need to change the location of PDF Studio user home folder. to a path without any Unicode / CJK characters.
- You have renamed/moved/deleted the “tess” folder under your user home folder. The “tess” folder is where all the downloaded language files are stored. PDF Studio’s OCR function will not work correctly if this folder has been modified.To solve this issue:
- Close the error message
- Exit PDF Studio
- Relaunch PDF Studio
- Re-download the language files
If this still does not work, download PDF Studio installer from Qoppa Software website and reinstall PDF Studio.
